|
Raghav Singhal I'm currently an AI PhD student in the Computer Science department at EPFL. I am fortunate to be advised by the amazing Prof. Robert West and am a contributor to the Apertus project (the biggest fully open and compliant training run & LLM at the time).Previously, I was a researcher at Massachusetts Institute of Technology and Mohamed bin Zayed University of Artificial Intelligence (MBZUAI), where I worked with Prof. Praneeth Vepakomma. Prior to this, I graduated from IIT Bombay with a Bachelor's in EE and a Master's in AI/ML. For EPFL students: If you are interested in a project, please feel free to reach out via mail. I'm very happy to supervise motivated students! |

|
ResearchMy research interests currently revolve around pretraining, data, and robust alignment of language models. Some of the projects I am currently working on include:
Check out my Google Scholar for a complete list of publications. * denotes equal contribution. Selected projects are highlighted. |
|
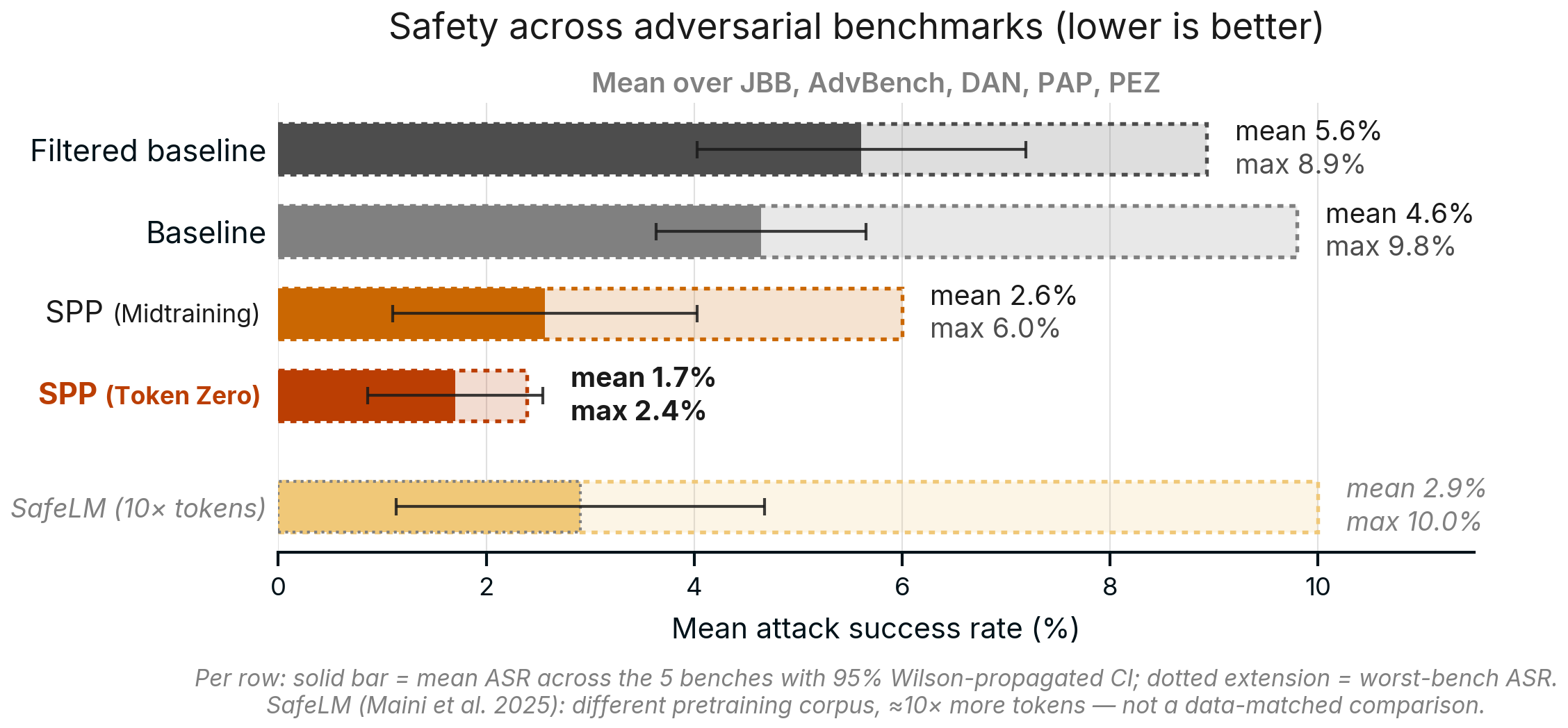
Synthetic Persona Pretraining: Alignment from Token Zero
Julian Minder*, Viktor Moskvoretskii*, Raghav Singhal*, Difan Jiao, Kartik Bali, Yiderigun Borjigin, Shaobo Cui, Stefan Krsteski, Ashton Anderson, Roland Aydin, Robert West Blogpost, 2026 blog post / X thread We propose Synthetic Persona Pretraining (SPP): append value-laden reflections to pretraining documents (10% annotated) to install the desired persona during pretraining rather than hope that it will emerge organically. SPP is very simple and purely a pretraining data intervention. Our results demonstrate that SPP models are consistently safer and more aligned than a range of baselines. |

|
Apertus: Democratizing Open and Compliant LLMs for Global Language Environments
Project Apertus arXiv / Hugging Face / Pretrain Code / Pretrain Data / Posttrain Code / Posttrain Data / Evals The biggest fully open and compliant training run & LLM at the time. 8B and 70B fully pretrained open-data open-weights models, multilingual in >1000 languages. Performance equivalent or better than corresponding Llama 3 sizes. |
|
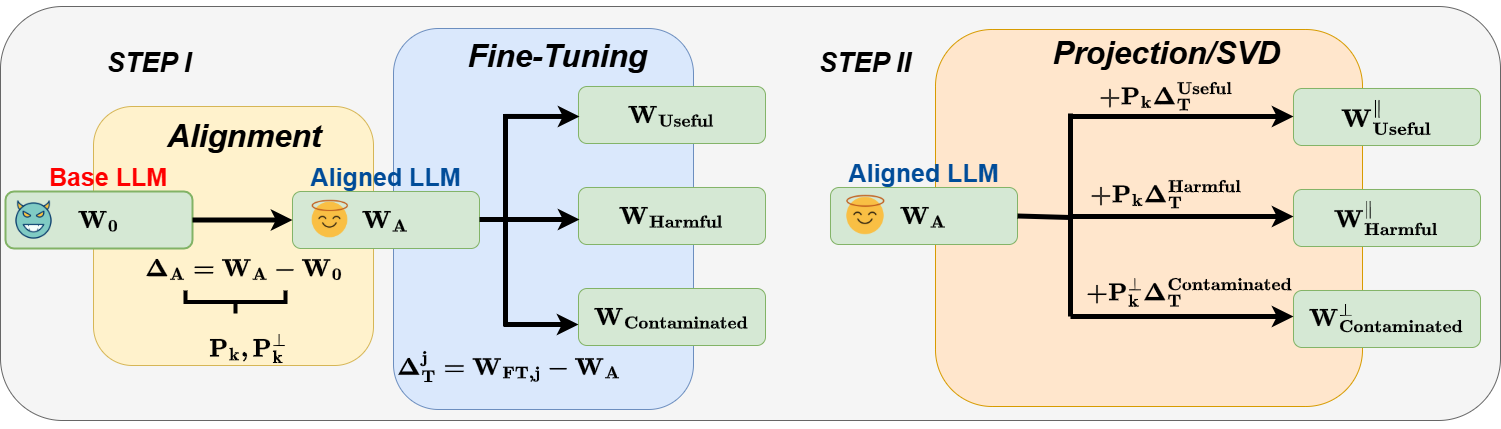
Safety Subspaces are Not Linearly Distinct: A Fine-Tuning Case Study
Kaustubh Ponkshe*, Shaan Shah*, Raghav Singhal*, Praneeth Vepakomma ICLR 2026 code / arXiv We show that safety alignment in LLMs is not confined to distinct subspaces (but rather, highly entangled with general ability directions), thus fundamentally challenging the foundation of subspace-based defenses. |
|
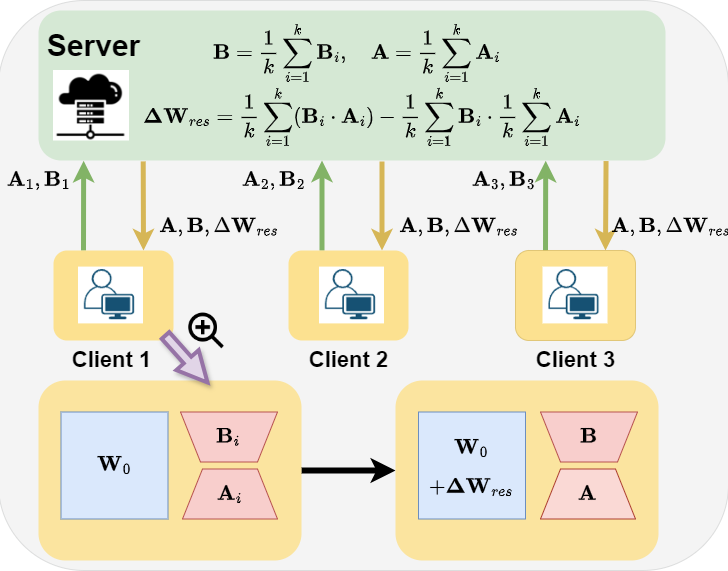
FedEx-LoRA: Exact Aggregation for Federated and Efficient Fine-Tuning of Foundation Models
Raghav Singhal*, Kaustubh Ponkshe*, Praneeth Vepakomma ACL 2025 - Oral (Top 2.2% of submitted papers) code / arXiv We achieve exact aggregation in distributed fine-tuning of LLMs, consistently improving over SOTA. |
|
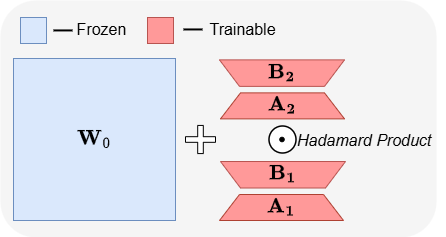
ABBA: Highly Expressive Hadamard Product Adaptation for Large Language Models
Raghav Singhal*, Kaustubh Ponkshe*, Rohit Vartak*, Praneeth Vepakomma ICLR 2026 Abridged at ES-FOMO @ ICML 2025 - Spotlight (Top 9.5% of accepted papers) code / arXiv We introduce ABBA, a PEFT method that enhances expressivity by decoupling low-rank updates from pre-trained weights via a Hadamard product, consistently improving over SOTA methods. |
|
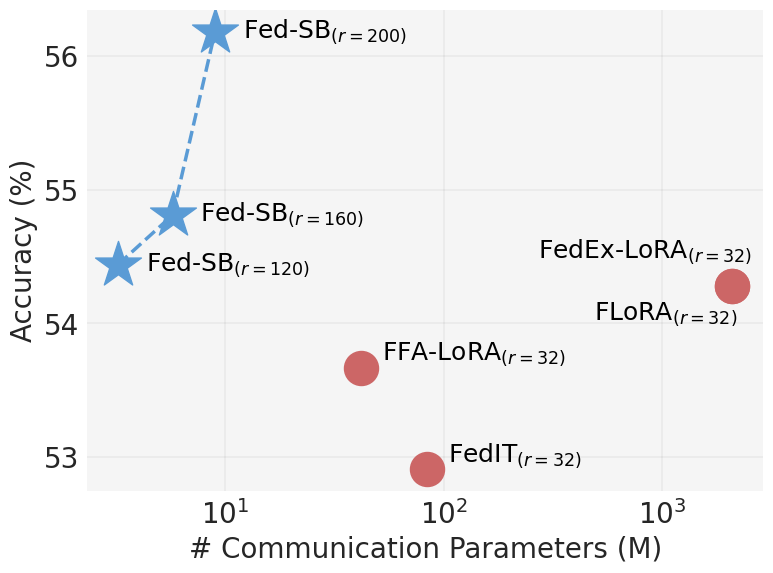
Fed-SB: A Silver Bullet for Extreme Communication Efficiency and Performance in (Private) Federated LoRA Fine-Tuning
Raghav Singhal*, Kaustubh Ponkshe*, Rohit Vartak, Lav Varshney, Praneeth Vepakomma NeurIPS 2026 | TMLR - J2C Certification (Top 10% of accepted papers) code / arXiv We set a new Pareto frontier for distributed fine-tuning of LLMs, achieving SOTA performance, stronger privacy guarantees, and up to 230x lower communication costs. |
|
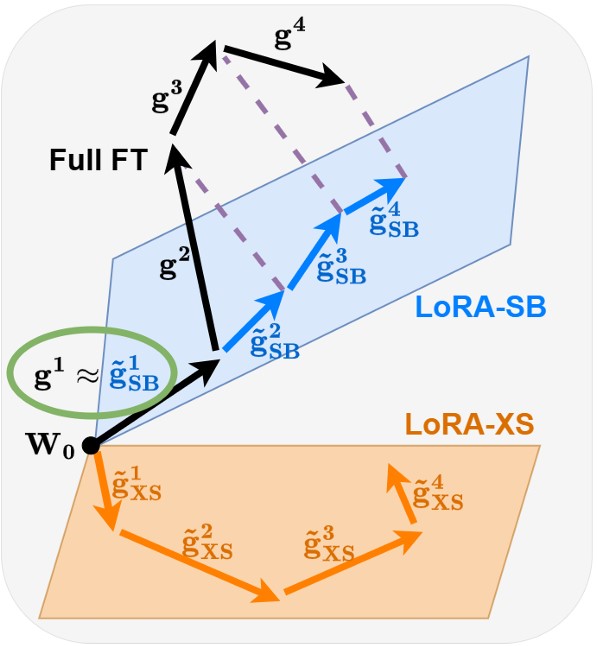
Initialization using Update Approximation is a Silver Bullet for Extremely Efficient Low-Rank Fine-Tuning
Kaustubh Ponkshe*, Raghav Singhal*, Eduard Gorbunov, Alexey Tumanov, Samuel Horvath, Praneeth Vepakomma Abridged at SCOPE @ ICLR 2025 code / arXiv We provably achieve the best approximation of full fine-tuning in low-rank spaces solely through clever initialization, outperforming LoRA while using up to 90x fewer parameters. |
|
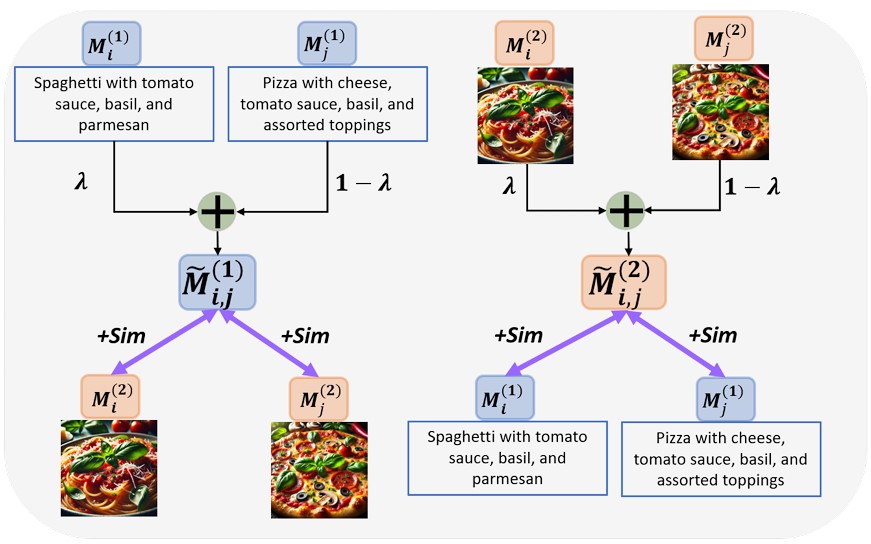
M3CoL: Harnessing Shared Relations via Multimodal Mixup Contrastive Learning for Multimodal Classification
Raja Kumar*, Raghav Singhal*, Pranamya Kulkarni, Deval Mehta, Kshitij Jadhav TMLR code / arXiv We introduce a multimodal mixup-based contrastive learning framework that effectively captures shared relations across modalities, enabling robust multimodal representation learning. |
|
Source code taken from Jon Barron's website. |